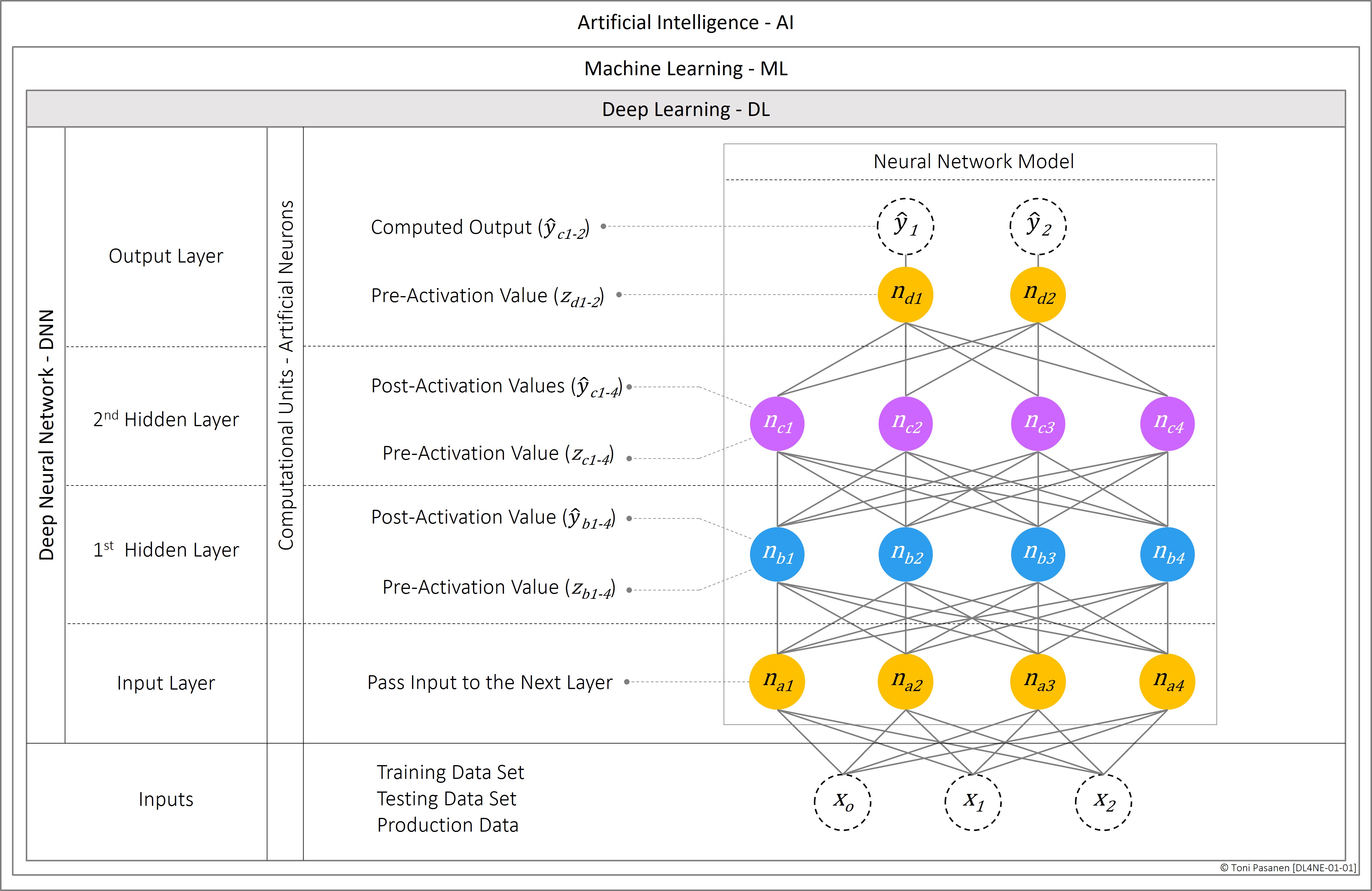
This chapter introduces the training model of a neural network based on the Backpropagation algorithm. The goal is to provide a clear and solid understanding of the process without delving deeply into the mathematical formulas, while still explaining the fundamental operations of the involved functions. The chapter also briefly explains why, and in which phases the training job generates traffic to the network, and why lossless packet transport is required. The Backpropagation algorithm is composed of two phases: the Forward pass (computation phase) and the Backward pass (adjustment and communication phase).
In the Forward pass, neurons in the first hidden layer calculate the weighted sum of input parameters received from the input layer, which is then passed to the neuron's activation function. Note that neurons in the input layer are not computational units; they simply pass the input variables to the connected neurons in the first hidden layer. The output from the activation function of a neuron is then used as input for the connected neurons in the next layer, whether it is another hidden layer or the output layer. The result of the activation function in the output layer represents the model's prediction, which is compared to the expected value (ground truth) using the error function. The output of the error function indicates the accuracy of the current training iteration. If the result is sufficiently close to the expected value, the training is complete. Otherwise, it triggers the Backward pass process.
In the Backward pass process, the Backpropagation algorithm first calculates the derivative of the error function. This derivative is then used to compute the error term for each neuron in the model. Neurons use their calculated error terms to determine how much and in which direction the current weight values must be fine-tuned. Depending on the model and the parallelization strategy, GPUs in multi-GPU clusters synchronize information during the Backpropagation process. This process affects network utilization.
Our feedforward neural network, shown in Figure 2-1, has one hidden layer and one output layer. If we wanted our example to be a deep neural network, we would need to add additional layers, as the definition of "deep" requires two or more hidden layers. For simplicity, the input layer is not shown in the figure.
We have three input parameters connected to neuron-a in the hidden layer as follows:
• Input X1 = 0.2 > neuron-a via weight Wa1 = 0.1
• Input X2 = 0.1 > neuron-a via weight Wa2 = 0.2
• Input X3 = 0.4 > neuron-a via weight Wa3 = 0.3
• Bias ba0 = 1.0 > neuron-a via weight Wa0 = 0.6
The bias term helps ensure that the neuron is active, meaning its output value is not zero.
The input parameters are treated as constant values, while the weight values are variables that will be adjusted during the Backward pass if the training result does not meet expectations. The initial weight values are our best guess for achieving the desired training outcome. The result of the weighted sum calculation is passed to the activation function, which provides the input for neuron-b in the output layer. We use the ReLU (Rectified Linear Unit) activation function in both layers due to its simplicity. There are other activation functions, such as hyperbolic tangent (tanh), sigmoid, and softmax, but those are outside the scope of this chapter.
The input values and weights for neuron-b are:
• Neuron-a activation function output f(af) > neuron-b via weight Wb1
• Bias ba0 = 1.0 > neuron-b via weight Wa0 = 0.5
The output, Ŷ, from neuron-b represents our feedforward neural network's prediction. This value is used along with the expected result, y, as input for the error function. In this example, we use the Mean Squared Error (MSE) error function. As we will see, the result of the first training iteration does not match our expected value, leading us to initiate the Backward pass process.
In the first step of the Backward pass, the Backpropagation algorithm calculates the derivative of the error function (MSE’). Neurons-a and b use this result as input to compute their respective error terms by multiplying MSE’ with the result of the activation function and the weight value associated with the connection to the next neuron. Note that for neuron-b, there is no next layer—just the error function—so the weight parameter is excluded from the error term calculation of neuron-b. Next, the error term value is multiplied by an input value and learning rate, and this adjustment value is added to the current weight.
After completing the Backward pass, the Backpropagation algorithm starts a new iteration of the Forward pass, gradually improving the model's prediction until it closely matches the expected value, at which point the training is complete.